Overview
By using the Cleanup Feature, you can filter and clean your data, ensuring your model is trained on high-quality data. Enhance data quality by inspecting outliers with metrics such as similarity, darkness, and blurriness. This application allows you to:
- Compare Similar Images: Easily identify and review images that are similar and avoid duplications, ensuring you have a diverse dataset.
- Assess Blurriness or Sharpness: Detect and manage images that are blurry, helping maintain high visual quality.
- Evaluate Darkness or Brightness Levels: Identify images with varying levels of darkness to ensure consistent lighting and visibility across your dataset.
Access the Cleanup Application
Get started with cleanup application by access the Cleanup tab from within the Dataset Browser to enhance data quality by inspecting outliers with metrics such as similarity, darkness, and blurriness.
Before You Begin - Prerequisites
To use the cleanup application, ensure that your dataset has the following:
Clip Feature Sets
CLIP (Contrastive Language-Image Pre-training) is a powerful neural network model trained on a massive dataset of image-text pairs. It excels at learning visual concepts and their connection to natural language descriptions.
- For image similarity analysis, CLIP is likely used to extract features from each image in the dataset.
- These features are essentially high-dimensional vectors (often 512 dimensions) that capture the essence of the image's visual content.
- CLIP doesn't directly create "Clip Feature Sets" but rather individual feature vectors for each image.
Once you have the CLIP features for each image, you can use various similarity analysis techniques. Here's the general workflow:
- Calculate similarity scores: You can employ different methods like cosine similarity to compare the feature vectors of two images. The higher the score, the more similar the images are visually.
- Retrieve similar images: Based on the similarity scores, you can rank or retrieve images closest to a query image. This allows you to find visually similar images within the dataset.
Extract the CLIP Features Sets
- In the Dataset Browser -> Data tab, click on the Select All. It selects all the items in the dataset.
- Click Dataset Actions.
- Select the Deployment slot -> Clip Extract Features from the list. The feature extraction process begins, and you can view the status in the Notifications bell icon.
Quality Scores
Quality scores are essential metrics in image datasets that help in assessing various attributes of images, such as blurriness and darkness. These scores enable Cleanup application to perform more accurate analysis and ensure that images meet certain quality standards.
Add Quality Scores to the Dataset
- In the Dataset Browser -> Data tab, click on the Select All. It selects all the items in the dataset.
- Click Dataset Actions.
- Select the Deployment slot -> Quality Score Generator from the list. The quality score generation process begins, and you can view the status in the Notifications bell icon.
Embeddings
Embeddings are numerical representations of data, typically in the form of high-dimensional vectors. These representations capture the semantics of the data, allowing for similarity comparisons between different data points. The Embeddings are required in the Cleanup application to perform the Similarly comparisons between images. When performing similarity comparisons, embeddings are crucial because they transform complex, unstructured data (like images) into a structured format that mathematical operations can handle.
Add CLIP Embeddings
If your dataset doesn’t have embeddings yet, no problem! Our platform supports the integration of Clip Embeddings, enabling you to initialize and leverage the cleanup feature effectively. This addition will help you streamline your data analysis, improving project outcomes.
Embeddings are crucial in a dataset for several reasons, particularly when dealing with complex or non-numeric data types like images. Machine learning algorithms require numerical input, so embeddings transform non-numeric data into a format these algorithms can process.
To add CLIP embeddings, if there are no embeddings available for your dataset:
From the Dataset Browser > Cleanup tab, click Add CLIP Embeddings. This will spin up a high-memory machine to execute CLIP model for extracting embeddings from all items in the dataset.
Similarity
The similarity feature in the Cleanup application allows you to identify similar images based on the similarity value. To use this feature, ensure Embeddings are available to perform the similarity comparison.
Similarity value: The value is between 0.001 to 0.15. By default, 0.01 is displayed. The least (0.001) value gives the more similar images.
When You Use Similarity Feature
Image Retrieval:
- Retrieve images similar to a given query image from a database.
- Rank the images based on similarity values.
Duplicate Detection:
- Detect duplicate or near-duplicate images in a collection.
- Flag images with very low similarity values
Cluster Analysis:
- Group similar images together into clusters.
- Use similarity values to form clusters with tight similarity.
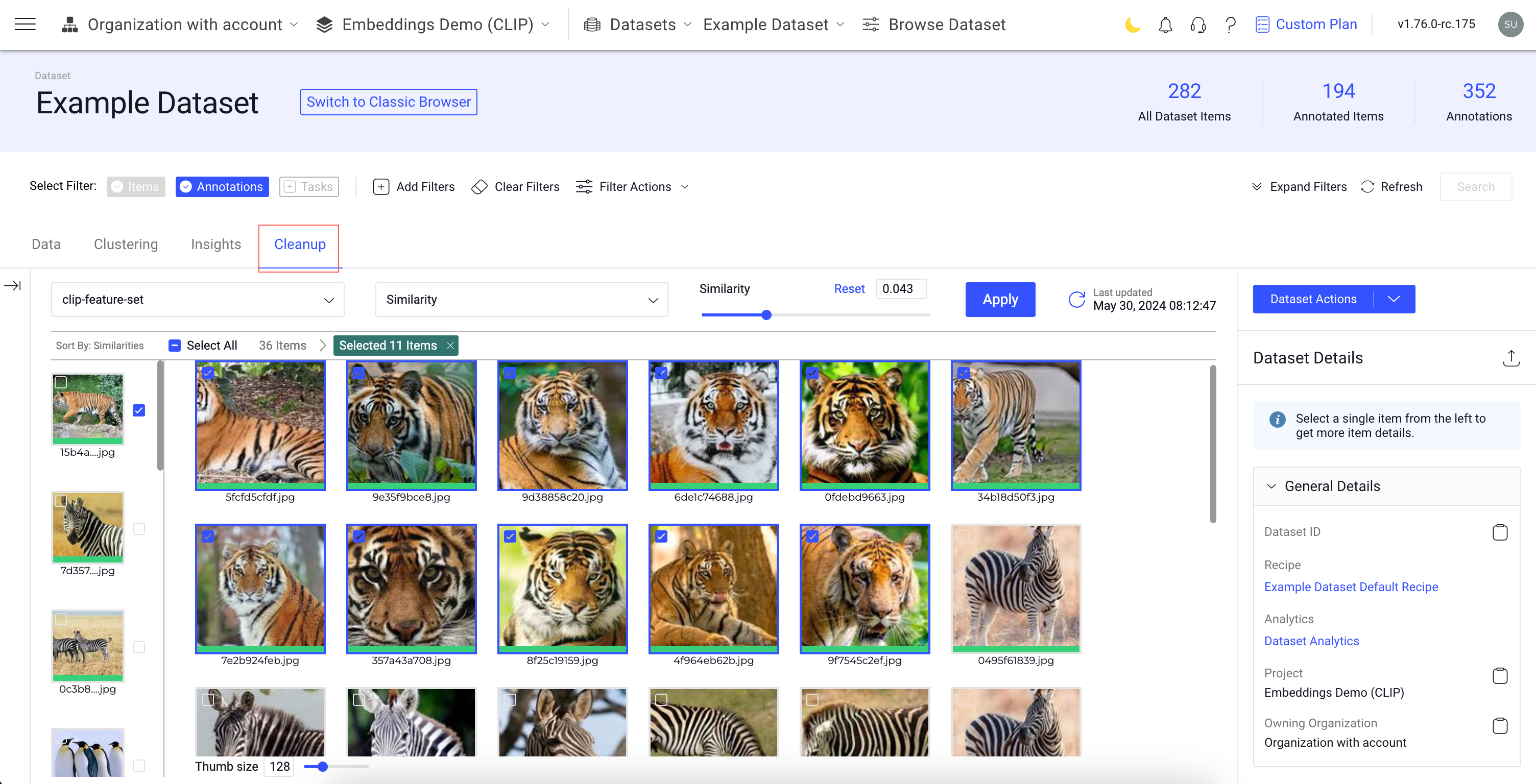
Identify Similar Images in Dataset
- Go to the Dataset Browser -> Cleanup tab.
- Select the Feature Set. You can use clip-feature-set, meta-clip-feature-set, or your own feature set.
- Select the Similarity value to define how closely the images should match.
- Click Apply. The Cleanup application will then display images that are similar based on the selected similarity value.
- The left column will show the base image (for example, Tiger) used to identify similar images in the dataset.
- Images similar to the base image are selected by default.
- Select different images (for example, Penguin, Cat, etc.) from the left column to view images similar to each of these base images.
- Use the Thumbnail size option to display more images.
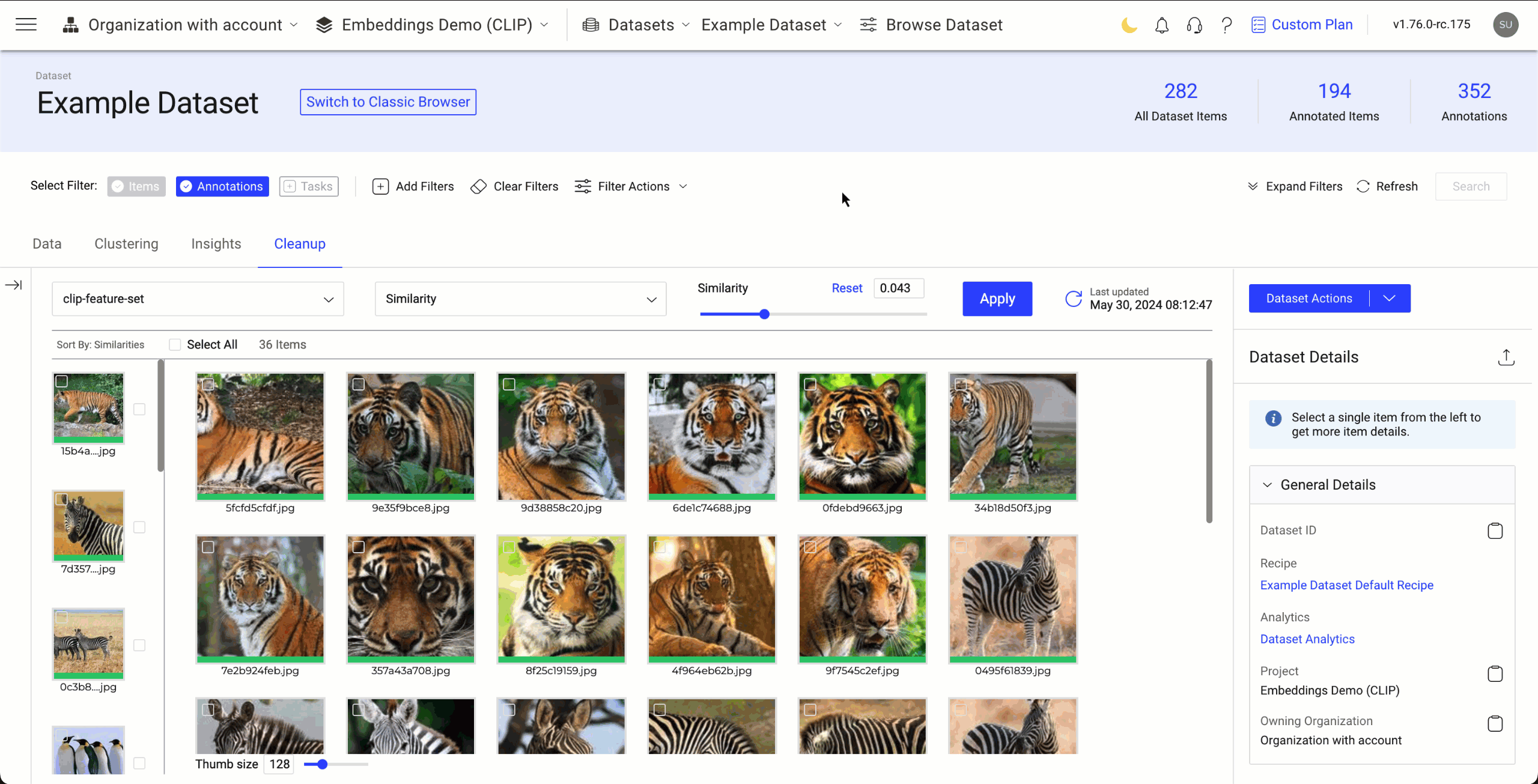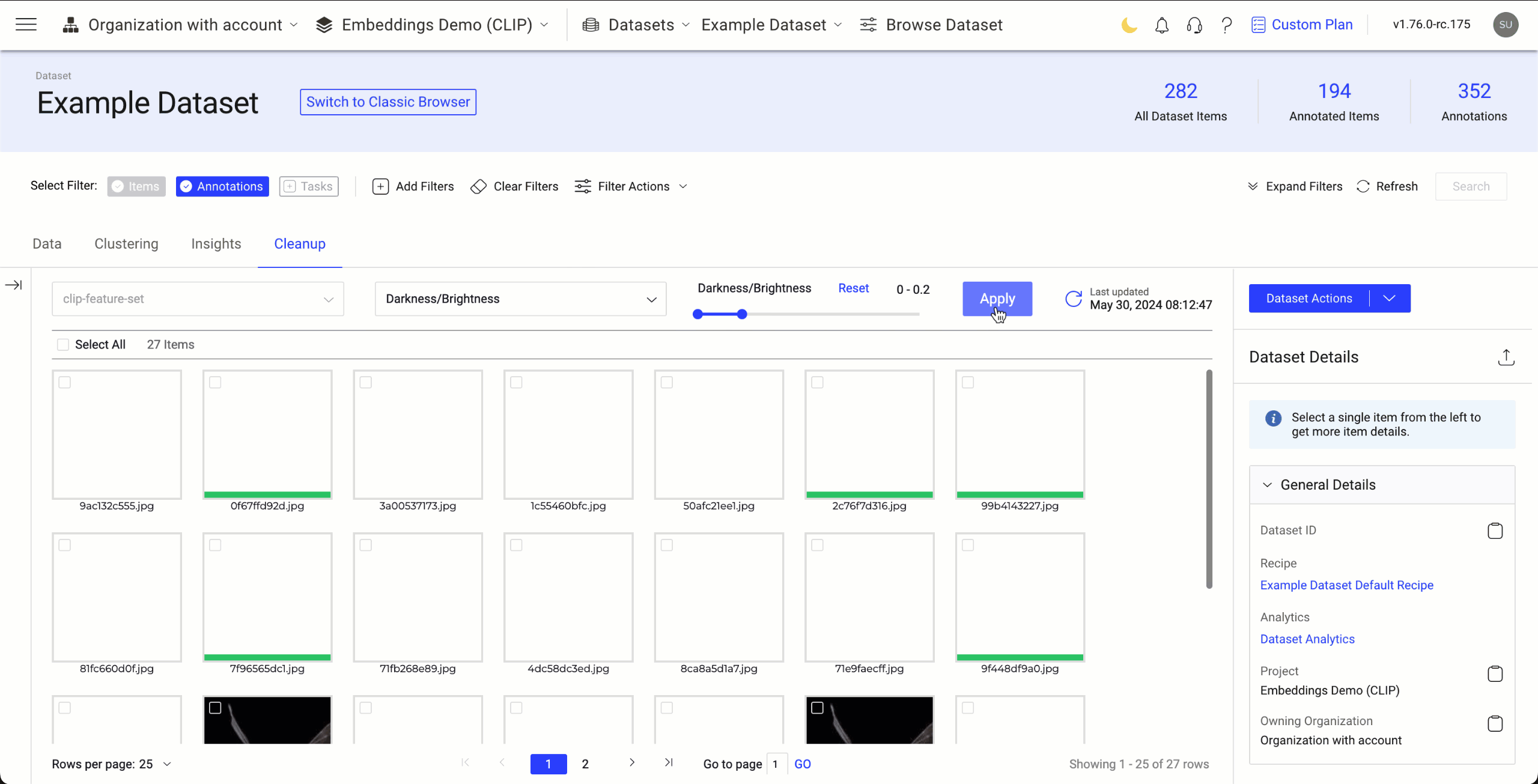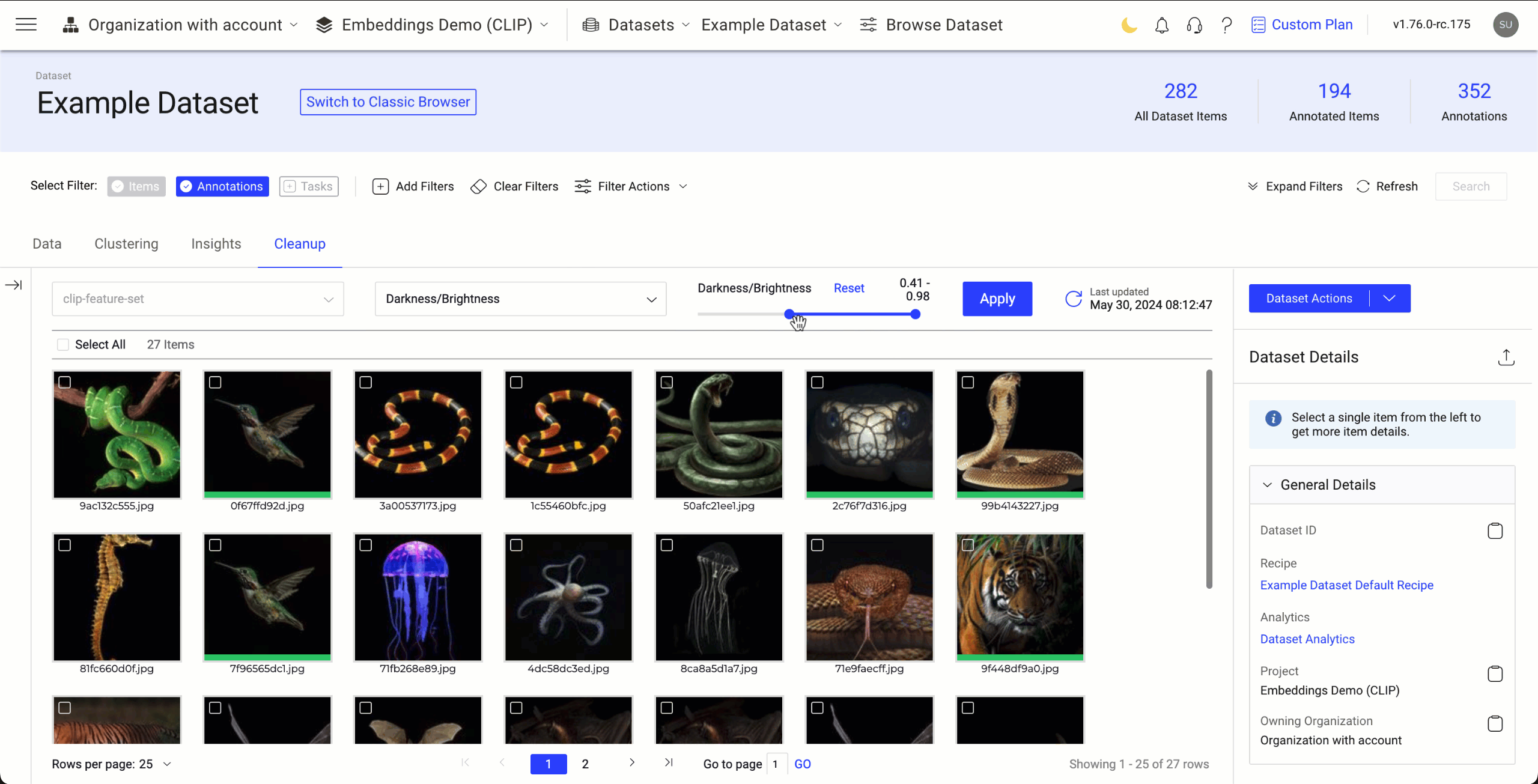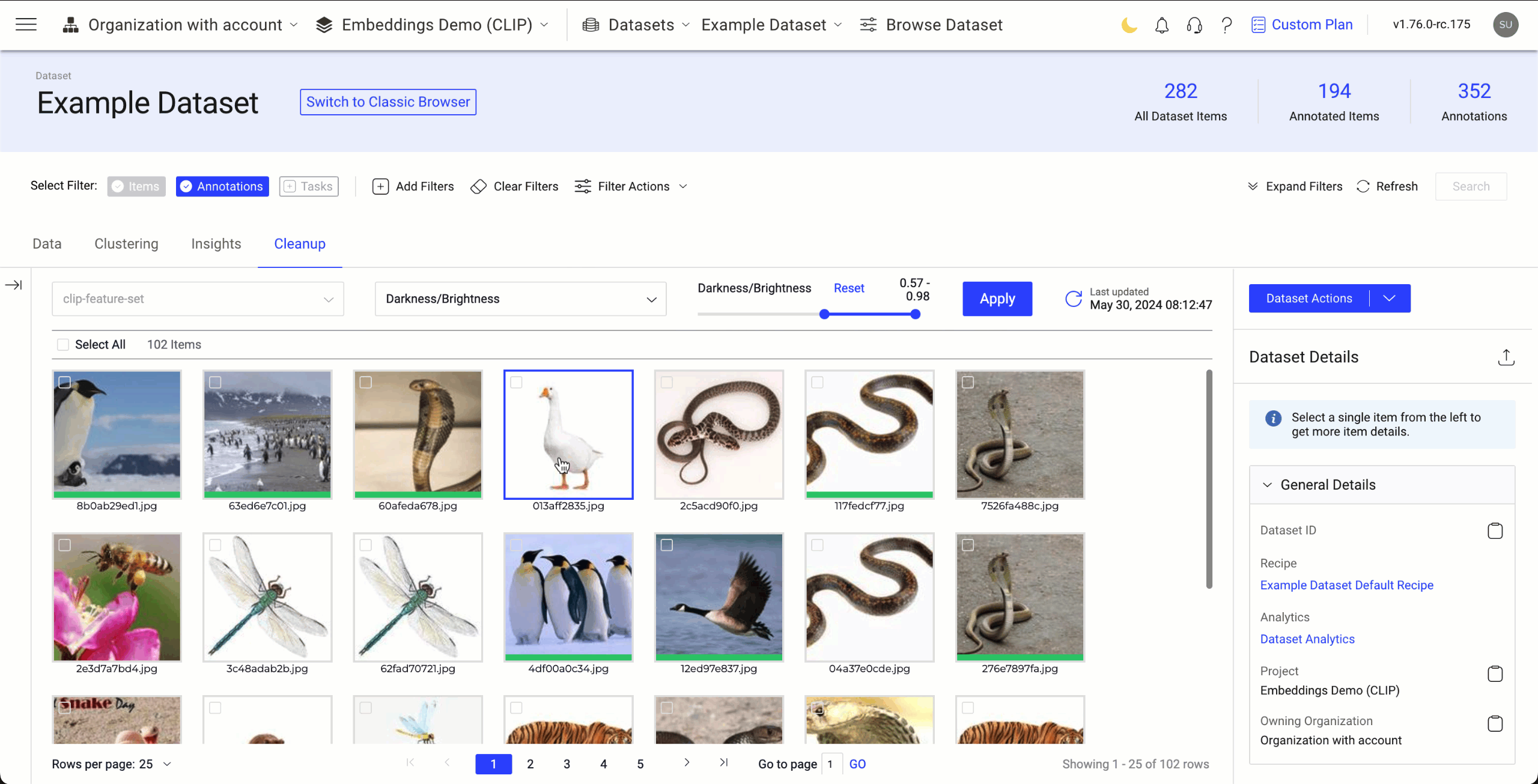
Darkness or Brightness
The darkness or brightness feature allows you to filter and view images in your dataset based on their brightness levels. This can be particularly useful for tasks such as enhancing image quality, detecting low-light conditions, or analyzing images based on their luminance.
Darkness/Brightness Level: The level is between 0 and 1. By default, 0 - 0.01 is displayed. The lowest (0.1) level gives the more darker images.
- The lowest value range gives the more darker images.
- The highest value range gives m ore brighter images.
Use the Darkness or Brightness Feature in a Dataset to View Darker or Brighter Images
- Go to the Dataset Browser -> Cleanup tab.
- Select the Darkness/Brightness option from the list. By default, Similarity is selected.
- Select the Darkness/Brightness range to define how darker or brighter the images.
- Click Apply. The Cleanup application will then display images that are darker or brighter based on the selected level.
Blurriness or Sharpness
The blurriness or sharpness feature helps you filter and view images in your dataset based on their level of clarity. This can be useful for tasks such as quality control, identifying out-of-focus images, and enhancing image processing workflows.
Blurriness/Sharpness Level: The level is between 0 and 1. By default, 0 - 0.01 is displayed.
- The lowest value range gives the more blurry images.
- The highest value range gives more sharper images.
Use the Blurriness or Sharpness Feature in a Dataset to View Blurry or Sharper Images
- Go to the Dataset Browser -> Cleanup tab.
- Select the Blurriness/Sharpness option from the list. By default, Similarity is selected.
- Select the Blurriness/Sharpness range to filter images based on their blurriness or sharpness.
- Click Apply. The Cleanup application will then display images that are blurry or sharper based on the selected value range.
Available Actions
There are many actions that you can perform in the Cleanup applications. In the right-side panel, click on the Dataset Actions and perform the required actions.
Refresh the Dataset
When there is a mismatch between the number of data items and their Feature Vectors in a data Cleanup application.
To fix this problem, it's recommended to refresh the extraction of the whole dataset to ensure that all items have feature vectors.
For example, if JSON files in the dataset lack feature vectors while other item types are included, so you will receive the following warning message once the clip extraction is completed.
"For some feature sets, the number of items is different from the number of feature vectors, please rerun the extraction on the whole dataset."
To rerun the entire dataset, follow instructions:
- Go to the Cleanup tab.
- Click on the Refresh icon next to the Last updated timestamp to ensure that you have the latest feature vectors.