January 31st, 2025 - v1.104.14
SDK Code to Manage Collections
Leverage the DDOE SDK to create, update, delete, and manage collections at both the dataset and item levels.
Dataset Level Methods: These methods operate on collections within a dataset.
dataset.collections.create(name: str): Create a new collection in the dataset. The dataset can have a maximum of 10 collections. The collection name must be unique within the dataset.dataset.collections.update(collection_id: str, new_name: str): Rename an existing collection. The new collection name must be unique.dataset.collections.delete(collection_id: str): Delete an existing collection. When deleted, the collection is automatically removed from all items assigned to it.dataset.collections.clone(collection_id: str): Clone an existing collection. The total number of collections in the dataset cannot exceed 10.dataset.collections.list(): Retrieve a list of all collections within the dataset.dataset.collections.list_unassigned_items(): List all item IDs in the dataset that are not assigned to any collections.
Item Level Methods: These methods work at the individual item level for managing collections.
item.assign_collection(item_id: str, collection_name: str): Assign an item to a specific collection. If the specified collection does not exist, it is created (subject to validation rules like maximum collections and unique names).item.unassign_collection(item_id: str, collection_id: str): Remove an item from a specific collection.item.list_collections(item_id: str): Retrieve all collections that an item is currently assigned to.
Below are examples of how to use these methods programmatically:
List all collections in a dataset:
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').collections.list_all_collections()
Create a new collection:
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').collections.create(collection='my_collection')
Clone a collection:
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').collections.clone(collection_name='my_collection_copy')
Delete a collection:
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').collections.delete(collection_name='my_collection_copy')
Rename a collection:
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').collections.update(collection_name='my_collection')
List unassigned items:
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').collections.list_unassigned_items()
Assign an item to a collection:
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').items.get(item_id='678fa1490d9f072defec6c5e').assign_collection(collections=['my_collection'])
Unassign an item from a collection:
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').items.get(item_id='678fa1490d9f072defec6c5e').unassign_collection(collections=['my_collection'])
SDK Code to Manage ML Subsets
This SDK code demonstrates how to filter dataset items, split them into ML subsets, assign specific items to a subset, remove an item from a subset, and retrieve items missing an ML subset in DDOE.
1. Filtering Items of Type ‘File’ and Splitting into ML Subsets
filters = dl.Filters(field='type', values='file')
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').split_ml_subsets(
items_query=filters,
percentages={'train': 60, 'validation': 20, 'test': 20}
)
- Creates a filter (filters) to select only items of type ‘file’ in the dataset.
- Uses split_ml_subsets() to distribute these items into Train (60%), Validation (20%), and Test (20%) subsets.
- Ensures balanced dataset partitioning for ML training.
2. Assigning a Specific Item to the ‘Train’ Subset
filters = dl.Filters()
filters.add(field='id', values=['678fa1490d9f072defec6c5e'], operator=dl.FiltersOperations.IN)
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').assign_subset_to_items(subset='train', items_query=filters)
- Creates an empty filter (filters) and adds a condition to select an item by its ID ('678fa1490d9f072defec6c5e').
- Uses assign_subset_to_items() to assign the selected item to the ‘train’ subset.
3. Removing an Item from Its ML Subset
filters = dl.Filters()
filters.add(field='id', values=['678fa1490d9f072defec6c5e'], operator=dl.FiltersOperations.IN)
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').remove_subset_from_items(items_query=filters)
- Filters an item by its ID ('678fa1490d9f072defec6c5e').
- Uses remove_subset_from_items() to remove the item from any assigned ML subset.
- The item will no longer belong to Train, Validation, or Test subsets.
4. Retrieving Items Without an Assigned ML Subset
dl.datasets.get(dataset_id='6785013bd25c9851e76313fd').get_items_missing_ml_subset()
- Fetches all dataset items that are not assigned to any ML subset.
- Useful for validating dataset completeness before training an ML model.
October 15th, 2023
Clone Items to Existing Datasets
Added SDK support for cloning a Dataset to destination dataset. A DQL filter can be delivered to clone only specific items from the Dataset.
May 1st, 2023 - Version 1.76.15
Add support for Python 3.11
A support for Python 3.11 was added.
Cross-Account integration for AWS
Added SDK supports for creating cross-account integration for AWS, to yield higher security.
Eliminated the need for users to create and maintain IAM for use with the DDOE platform. You can now assume the role of a DDOE ARN.
For more information and detailed setup instructions, read here.
Bug Fix: Add/Update attributes in frames
Updating annotation attributes for a specific video frame and uploading a new annotation with a value set for its attribute was fixed.
# Example 1: When updating annotation
ann = item.annotations.list()[0]
ann.frames[50].attributes = {"1": True, "2": ["2"]}
ann.update()
# Example 2: When uploading annotation
builder[0].add_frame(
dl.Classification(label='person', attributes={"1": True, "2": ["2"]}),
frame_num=50,
fixed=False
Oct 25th, 2022 - Version 1.66.22
Pipeline: Create pulling task node
Starting from this version, you are able to create task node with a pulling allocation method in a pipeline from the SDK easily.
To enable pulling methold, you will have to define the pulling params in the task node param list:
1. batch_size
2. max_batch_workload (max items)
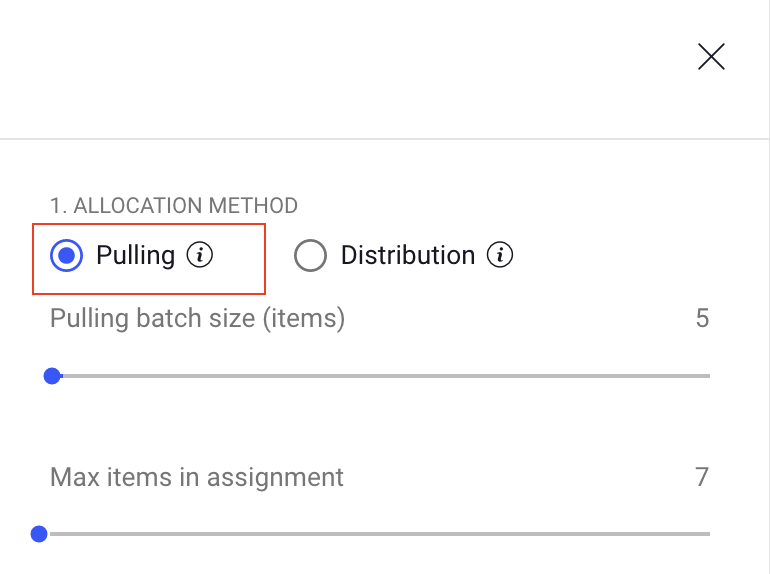
To read more about pulling task, including batch size and max batch workload , please click here
p = dl.pipelines.get(pipeline_id='632c4f428c9e0ece058f3caa')
n = dl.TaskNode(name="myTask",
project_id="b09cd8b4-359d-4692-b693-dbc674c0213b",
dataset_id="630de80dc74f1b7f37eab189",
recipe_title="images Default Recipe",
recipe_id="630de80d5127a4bbd216e1fa",
task_owner="user@mail.com",
workload=[dl.WorkloadUnit("ann1@mail.com", 50),
dl.WorkloadUnit("ann2@mail.com", 50) ],
task_type='annotation',
batch_size=5,
max_batch_workload=7,
priority=dl.TaskPriority.LOW)
p.nodes.add(n)
p.update()
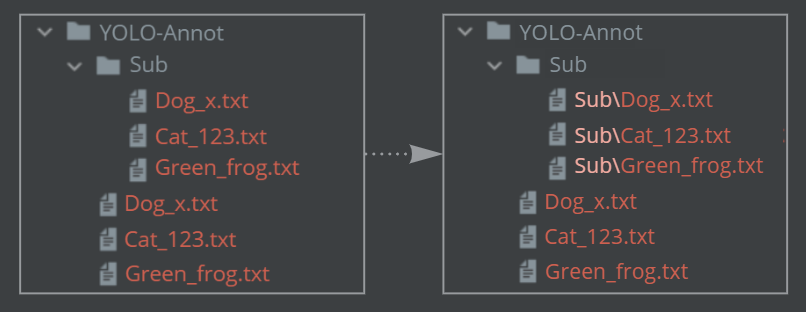
Fix Uploading Items from YOLO & VOC Formats: Support Sub-directories
Uploading Items from YOLO and VOC formats now supports the following (COCO format is already supported):
When uploading a folder to a DDOE dataset, if there are duplicate named files in any of the subfolders (same as in the root folder), please update the file names in the subfolder to include the relative path, in order to upload all files at once.
Duplicate named files in subfolders, that won't be updated, will be skipped.
For example:
Aug 8th, 2022 - Version 1.63.10
Item & Annotation Description Migration
From this release on, Item.description & `Annotation.description become root properties of item/annotation entities, and are removed from the system metadata.
Your action is required by to ensure continuous work. Please check our documentation to get updated with all the relevant implications here.
Driver Deletion
This release enables to use the SDK to delete a driver connected to the dataset. This is performed using the following:
project = dl.projects.get(project_id="<relevant project id>")
driver = project.drivers.get(driver_name='<relevant driver name>')
driver.delete(True, True)
July 25th, 2022 - Version 1.60.9
Revision of item.annotations.download() - Mask to JSON
Taking effect with this release, the default type of annotation download has changed from mask to JSON.
June 29th, 2022 - Version 1.59.4
Deprecation of "multi" parameter in Recipe Attributes 2.0
A deprecation of the “multi” parameter in function
update_attributes()
is scheduled for the future SDK release of version 1.60.0.
Starting from this release (1.59.4), a deprecation warning will appear whenever this parameter is used.
multi is no longer needed to indicate attributes with multi/single selection:
To create a multiple selection Attribute (checkbox), use
*dl.AttributesTypes.CHECKBOX*
.
To create a single selection Attribute (radio-button), use
dl.AttributesTypes.RADIO_BUTTON
.
Other available attributes types (won’t be affected): YESNO, FREETEXT, SLIDER (e-num).
Revision of item.annotations.download() - Mask to JSON
On future release of version 1.60.0, the default value of "annotation_options" parameter in annotations.download() function will be changed from [dl.ViewAnnotationOptions.MASK] to [dl.ViewAnnotationOptions.JSON].
Starting from this release (1.59.4), a deprecation warning will appear whenever this function is used.
Requirements Upgrade
Upgraded versions of the following libraries are now available:
- diskcache>=5.4
- redis>=4.3
- aiohttp>=3.8 (to support redis update)
June 14th, 2022
Attribute 2.0 Creation in Recipe
Attribute 2.0, which supports checkbox, radio-button, free-text and more, can now be created and added to a recipe using the SDK.
For example:
recipe = dl.recipes.get('604e46143d5a53f65b3441e7')
ontology = recipe.ontologies.get(ontology_id='604e461472481317b3d32f54')
ontology.update_attributes(key='1', title='New Attribute', attribute_type=dl.AttributesTypes.CHECKBOX, values=[123])
Pipeline Reset
Resetting the pipeline clears all clounter, as well as pending items and cycles (logs and executions are not affected). By default it is not possible to reset a pipeline that is in Run mode, but it can be enforced using the stop_if_running=True option. Read more.
#To reset the pipeline:
project.pipelines.reset(pipeline='pipeline_entity', stop_if_running=True)
#To see the pipeline statistics:
project.pipelines.stats(pipeline='pipeline_entity')
Create Pulling Task
Pulling tasks (Labeling/QA) can now be created from the SDK, where each assignee is allocated with only X number of items at a time (batch size), and new items are pulled by demand, according to the progress of work, and considering parameters such as batch_size and max_batch_workload. Read more.
t = dataset.tasks.create(batch_size=3, allowed_assignees=['mohamed@dataloop.ai'], max_batch_workload=5, task_name='aa')
Repeating/Recurring status events
When creating a pipeline node and using the parameter repeatable=True, the pipeline will generate status events on items )for example: Completed, or Discarded) EVERY time an item receives a status in a specific node, and not just in the first time. For example if Discaring an item in a task, a matching status event will be triggered. Changing the item’s status to Completed will then trigger another event.
#This option is enabled by default.
metadata: {position: {x: 455, y: 235, z: 0}, repeatable: true}
For more examples, please read “Pipeline Task Node - Rerun”.
Annotation.geo() Deprecation
The annotation.geo() function for box representation will be revised to return 4 points instead of 2 points, due to be updated in SDK future version 1.62.0.
The results of annotation.geo() as of now:
[[378.12, 178.51], [682.81, 401.78]]
The results of annotation.geo() after the revision:
[[378.12, 178.51], [378.12, 401.78], [682.81, 401.78], [682.81, 178.51]]
April 5th, 2022
- Remove Item/s from Task
Now, items that are not in status "Completed" can be removed from a task.
def remove_items(self, filters: entities.Filters = None, query=None, items=None, wait=True):
A single item or multiple items can be removed from a task. For example:
t = dl.tasks.get(task_id='<task_id>')
items = list(t.get_items().all())
t.remove_items(items=[items[0], items[1]])
-
The Account field in Organization used to be list of dictionaries. Now it is a single dictionary.
-
"platform_url" and "open_in_web" have been added to dl.Filters. "platform_url" returns the link to item in the browser and "open_in_web" opens the item in the browser.
# platofrm_url
dataset = dl.datasets.get(None, '<dataset_id>')
dl.Filters('name', '<filename>').platform_url(dataset)
# open_in_web
dataset = dl.datasets.get(None, '<dataset_id>')
dl.Filters('name', '<filename>').open_in_web(dataset)
- Use the function
dl.AnnotationCollection.from_json_file(path)to create an annotation object from a JSON file and add an item to the annotation object.
item = dl.items.get(item_id='<item_id>')
annotations = dl.AnnotationCollection.from_json_file(filepath='<filepath>', item=item)
print(annotations[0].dataset.name)
- Use the
item.resource_executions.list()function to get all the executions for an item:
item = project.items.get(item_id='<item_id>')
for page in item.resource_executions.list():
for exec in page:
print(exec)
March 9th, 2022
Upload Annotations with User Metadata
To upload annotations from JSON and include the user metadata, add the parameter local_annotation_path to the dataset.items.upload function, like so:
dataset.items.upload(local_path=r'<items path>', local_annotations_path=r'<annotation json file path>', item_metadata=dl.ExportMetadata.FROM_JSON, overwrite=True)
Visit our SDK documentation for tutorials on Uploading and Managing Annotations.
March 2nd, 2022
SDK Converter Utility
The SDK converter utility documentation is available here.
Exporting Files with File Extension as Part of the Filename
Files can now be exported from the dataset with the file extension as part of the exported filename.
The export_version param in dataset.download() can be set to ExportVersion.V1 or ExportVersion.V2 to avoid duplication of files with different extensions. This allows items with the same filename and different extensions in the dataset to be saved as different items.
Old functionality (V1) – abc.jpg → annotations are saved as abc.png and the JSON is saved as abc.json
New functionality (V2) – abc.jpg → annotations are saved as abc.jpg.png and JSON is saved as abc.jpg.json
For example:
dataset.download(local_path=r<'path'>, annotation_options='json',
export_version=dl.ExportVersion.V2)
Param export_version will be set to ExportVersion.V1 by default.
For more information on the dataset.download() function click here.
Deleting a Recipe That Is Connected to a Dataset
If you wish to delete a recipe that is connected to a dataset, you must add the parameter force=True to the delete() function to be able to delete the recipe:
# This command is only for DELETED datasets
dataset.recipes.get(recipe_id='my_recipe_id').delete())
# To delete a recipe that is connected to a dataset, you must add the param force=True to the delete function
Click here for basic SDK commands affecting Recipes and Ontology.
See our repository for complete information on the Recipes class and delete function.
January 31st, 2022
- The functions
create()andcreate_qa_task()in class Tasks can take the parameter available_action to create an action/status for the task (e.g., complete, discard, approved).
- Now, when adding a function to FaaS, you can add the parameter context to the function, and an object will be created for you with the following attributes:
context.service → the service used
context.project → the project used
context.package → the package used
context.logger → the logger used
context.sdk → the dl object used
context.progress → the progress object used
context.task_id → the id of the task, in case it arrives from a specific task
context.task → the task, in case it arrives from a specific task
context.assignment_id → the assignment id, in case it arrives from a specific task
context.assignment → the assignment, in case it arrives from a specific task
context.item_status_creator → user who changed item status, in case of item status change
context.item_status → item status, in case of item status change
context.item_status_operation → the action, in case of item status change
context.pipeline → pipeline
context.node → node
context.execution → the specific execution
context.pipeline_execution → pipeline cycle execution
For example, you may add context to the function run() in the following manner:
def run(item, context):
print(context.service)
January 26th, 2022
Users can activate UI Slots from the SDK with the service.activate_slots function:
service.activate_slots(project_id=''", slots=slots)
Users can create a pipeline through the SDK by providing a pipeline_name and project_id:
project = dl.projects.get(project_id=<”project_id”>)
pipeline = project.pipelines.create(name=<”name”>, project_id=<”project_id”>)
Click here for more information about class Pipelines functions.
January 11th, 2022
When updating item status, you will need to provide the task_id or assignment_id as the item may be included in a number of tasks/assignments.
January 3rd 2022
Now in package.push there is the ability to add requirements.
For example, if your code requires openCV to run, you will need to specify openCV as a requirement.
To set requirements:
package = project.packages.push(
src_path='<path_to_file>',
package_name=package_name,
modules=[module],
requirements=[
dl.PackageRequirement(name='<name>'),
dl.PackageRequirement(name='<name>', version='<version>'),
dl.PackageRequirement(name='<name>', version='<version>', operator=<operator>)
]
)
Requirements can be added through this script or added as a separate file in the directory that is pushed.
Added creator attribute to item: item.creator