DDOE enables seamless dataset management by allowing you to sync data from external cloud storage providers. This flexibility ensures efficient data organization and easy accessibility within the platform.
Sync Cloud Storage Data
DDOE provides the capability to synchronize data from external cloud storage platforms. Users can connect their DDOE accounts with popular cloud storage services such as Amazon S3, Google Cloud Storage, or Microsoft Azure, and seamlessly transfer data between these platforms and DDOE.
Syncing data allows users to leverage existing data stored in external cloud services within the DDOE environment, enabling them to centralize and manage all their data in one place.
Prerequisites for Syncing a Storage Driver
To integrate your cloud storage services, see the Integrations Overview article.
To connect your cloud storage and sync files to DDOE using the SDK, see the Data Management Tutorial.
To sync the storage driver:
In the Data Browser page, click the Sync Storage Driver icon available on the right-side panel. The Initiate External Storage Sync popup is displayed.
Click Sync Data.
Key points
Here are the key points to keep in mind when initiating the cloud storage sync process:
Verify Write Access: Make sure you have write access to save thumbnails, modalities, and converted files to a hidden
.DDOEfolder on your storage.Permission Validation: As part of the process, a permission
test-fileis added to your storage folder to validate the necessary permissions.Annotations and Metadata: It's important to note that annotations and metadata are stored on the DDOE platform, separate from your external storage.
Deletion Handling: If you delete a file from your external storage, you may need to initiate a file deletion process in DDOE or set up an Upstream sync in advance to ensure that these events are properly managed and accounted for.
Setup Process
The setup process for external storage includes the following instructions:
Prepare External Storage: In your external storage account (AWS S3, Azure Blob, GCP GCS, or Private Container Registry), ensure you have the necessary credentials and permissions for use by DDOE. Specific instructions for each storage type are provided:
List (Mandatory): Allowing DDOE to list all items in the storage.
Get (Mandatory): Allowing retrieval of items and performing pre-processing functions like generating thumbnails and fetching item information.
Put/Write (Mandatory): Enabling you to upload your items directly from the DDOE platform to the external storage.
Delete: Allowing you to delete items directly from the external storage using the DDOE platform.
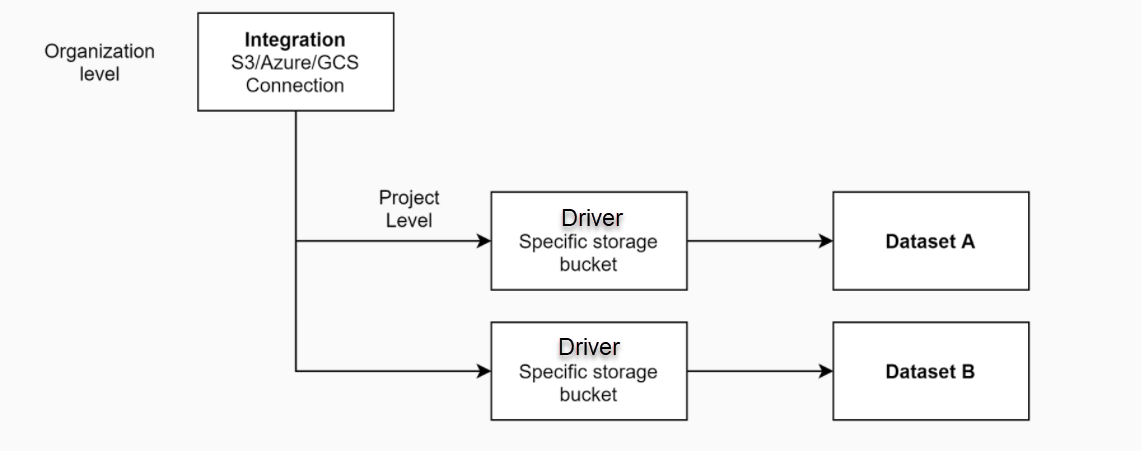
Create Integration in DDOE Organization: Within your DDOE Organization, set up a new Integration to input the credentials prepared in the previous step. These credentials are securely saved in a Vault and can be utilized by projects owned by the organization.
Generate Storage Driver: In a specific project, create a new storage driver. To create a new storage-driver, see the Storage Drivers overview and relevant steps, such as for AWS, GCP, or Azure cloud providers.
Create a Dataset and Configure: In the same project, create a new Dataset and configure it to use external storage by employing the storage driver you've already created. This configuration will ensure that the dataset interacts with and stores data on the specified external storage resource.
Initial Sync
When your dataset is configured correctly, an initial synchronization operation begins automatically. For a successful completion of this process, the following conditions must be met:
Ensure that your integration credentials are valid and have the necessary permissions.
When creating the dataset, be sure to enable the Sync option. If you don't enable it during dataset creation, you can initiate the sync process manually from the dataset browser.
Ensure that you have an adequate number of available data-points in your quota. You should have enough data-points that match the number of file items you intend to synchronize.
Once the sync process begins, you can monitor its progress in the notifications area to ensure that all data items are properly indexed and synchronized.
Ongoing Sync: Upstream and Downstream
After connecting your cloud storage to a dataset and completing the initial sync, the dataset reflects your directory structure and file content. Managing your files within the dataset, including actions like moving between folders, cloning, merging, etc., acts as an additional layer of management and does not impact the binary files in your cloud storage.
Syncing Empty Folders: The platform does not display the syncing of empty folders from your storage.
Moving or Renaming Items: If you move or rename items on your external storage, it will result in duplicates within the platform.
Saving New Files: The DDOE platform saves newly generated files inside your storage bucket under the folder /.DDOE. This includes items like video thumbnails, .webm files, snapshots, etc.
Limitations on Renaming or Moving Items: You cannot rename or move items within the DDOE platform if they are linked to an external source.
Cloning Items: Items can only be cloned from internal storage (DDOE cloud storage) to internal storage or from external storage to the same external storage.
Important
Sync will update only the items that have changed since the last synchronization.
Cloned and merged datasets cannot be synced on the DDOE platform because they are not directly indexed to external storage.
Downstream
Downstream sync is the process of updating any file-item changes from your DDOE platform (for example, the dataset - adding/deleting files) into your external storage (or original storage). Downstream sync is always active.
New files: If you decide to add new files directly to your DDOE dataset, bypassing your external storage, DDOE will make an effort to write these new files to your external storage to ensure synchronization.
File deletion: By default, DDOE does not automatically delete your binary files. Any files deleted from DDOE datasets will not be removed from your cloud storage. If you wish to enable the deletion of files and have your cloud storage reflect changes made within the DDOE platform, you need to explicitly select the Allow delete option. Ensure the following:
Allow deletion permissions in your IAM for AWS, GCS, and Azure.
Check the Allow delete option in the storage driver.
Important
If items are deleted from DDOE while Allow Delete is set to false (not selected), they will not be restored when re-syncing the storage driver.
File Moving: Moving items within a dataset that resides on external (read-only) storage is not possible. This is a designed limitation, since DDOE cannot physically move files in your storage without causing mismatches between the dataset and the actual storage structure.
Upstream
Upstream sync is the process of updating any file-item changes from your external storage to the DDOE platform. There are various ways in which upstream sync occurs:
Important
Sync will update only the items that have changed since the last synchronization.
Automatically, Once: This happens at the time the storage driver is created, assuming the option was enabled during dataset creation.
Manually: You can initiate this process each time you click Sync for a specific dataset, accessible through the Dataset browser. This action triggers a scan of the files on your storage, indexing them into DDOE. Keep in mind that files deleted from the cloud storage might persist as 'ghost' files in your dataset.
Automatic Upstream sync: DDOE provides a code that can monitor changes in your bucket and update the respective datasets accordingly. It enables automatic upstream synchronization of your data when file items are modified. For more information, see the AWS, Azure, and GCP article.