Overview
Services are configured with a runtime driver and runtime configuration, which defines how the Service should be deployed.
Currently, the only supported driver is the Kubernetes driver. When a Service is deployed with the Kubernetes driver, a Kubernetes deployment is created.
A Kubernetes deployment tells Kubernetes how many replicas of the Service must be up at any point in time, and how many resources should be allocated.
The amount of resources each replica has is determined by the instance type of the Service. Whether the Service has a GPU and what the GPU type is also determined by the instance type.
The Agent is a pod that runs a Dataloop code that loads the Module, listens to a RabbitMQ queue and for each message, invokes the relevant function in the Module with inputs parsed from the message, manages the status updates, Monitors executions, updates metrics, all the service overview, CPU statuses, etc. The agent will be terminated when the service is down.
Each time an execution is created manually or through a trigger, a message is sent to the relevant queue in RabbitMQ, which in turn invokes the relevant function in one of the Agents.
Rolling Updates
To provide zero downtime on Service updates, our updates are implemented with a rolling update mechanism.
When a Service update is invoked, our backend picks a couple of Agents, tells them to stop consuming new messages from RabbitMQ, waits for the existing executions to finish, and then exits.
When an Agent exits, a new Agent is created instead of it, configured with the updated parameters.
If an Agent does not terminate since being ordered to stop, it is brutally stopped, regardless if it finished handling all executions that it fetched or not.
Update App Configuration - UI
Follow the steps to:
- Update an Existing Service
- When installing a new app (creating a service)
- Existing package
To update the service (App) configuration of your services:
- Open CloudOps from the left-side portal menu.
- Click on the service you want to update. A detailed right-side panel is displayed.
- Click on the Service Actions > Edit Settings. The Installation Configuration dialog window is displayed.
- Click Advanced to open the service configuration dialog and make the changes.
- Click Confirm.
When creating a new package:
- Click on the App Config button to edit the default service configuration.
- Now you can edit the default configuration of your app. When installing the app to create a service, the service will use the settings you defined.
Concurrency
Concurrency is the number of parallel executions that can run simultaneously. Each execution will start a new thread or a process, depending on the service run_execution_as_process flag. When deploying a service, we can set its concurrency (the default is 10):
service = package.deploy(
service_name='my-service',
runtime=dl.KubernetesRuntime(concurrency=32)
)Machine Type
Machine Type refers to the different configurations of computational resources that you can choose from, depending on the requirements of your tasks. Dataloop offers several instance types, each optimized for different use cases, ranging from general-purpose to high-memory and GPU-accelerated tasks:
| DL Instance types | Runner CPU | Runner RAM | GPU |
|---|---|---|---|
| Regular-XS | 0.5 | 2GB | - |
| Regular-S | 1.5 | 6GB | - |
| Regular-M | 3 | 12GB | - |
| Regular-L | 6 | 24GB | - |
| Highmem-XS | 0.5 | 4GB | - |
| Highmem-S | 1.5 | 12GB | - |
| Highmem-M | 3 | 24GB | - |
| Highmem-L | 7.15 | 48GB | - |
| GPU-T4 | 1 | 7.5GB | 1 |
| GPU-T4-M | 2 | 13GB | 1 |
| GPU-K80-S | 2 | 7.5GB | 1 |
| GPU-K80-M | 2 | 13GB | 1 |
To set the pod type:
If no machine type is specified, the default type regular-s will be selected.
service = package.deploy(
service_name='my-service',
runtime=dl.KubernetesRuntime(pod_type=dl.InstanceCatalog.HIGHMEM_L)
)- Regular instances (regular-xs, regular-s, regular-m, regular-l) are suitable for standard workloads that require varying degrees of CPU and RAM.
- High memory instances (highmem-xs, highmem-s, highmem-m, highmem-l) are optimized for tasks that require more RAM relative to CPU resources.
- GPU instances (gpu-k80-s, gpu-k80-m) are designed for tasks that benefit from GPU acceleration, such as machine learning and deep learning workloads, with specific GPU types like the K80 model.
Num Replicas
When you have large loads of work to do, you can create a few replicas of the same service:
service = package.deploy(
service_name='my-service',
runtime=dl.KubernetesRuntime(num_replicas=2)
)Autoscaler
When we have changing loads of work, we want the number of replicas of the service to scale up when there are many executions coming in, and scale down otherwise. To do so, we need to create an autoscaler:
- 'cooldown_period' - Define how long to wait before scaling down (reducing the number of replicas) in case the queue is empty again. So that running executions will have time to complete.
- 'polling_interval' - Autoscaler polling interval of the service queue (in seconds). This parameter defines how often a new execution enters the queue.
service = package.deploy(
service_name='my-service',
runtime=dl.KubernetesRuntime(autoscaler = dl.KubernetesRabbitmqAutoscaler(
# If you set the min_replicas to 0 the service won’t run until it has something in the queue, it will be suspended
# the following parameters are also the default
min_replicas=0,
max_replicas=1,
queue_length=10,
cooldown_period=300,
polling_interval=10
))
)Service SDK Version Update
The SDK version for a service can be updated from the Dataloop platform user interface and from the SDK.
From the UI
- Select CloudOps > Services.
- Select or search the service from the list.
- Click on the Service Actions.
- Select the Edit Service Settings.
- Click Advanced.
- Select the SDK version in the SDK Version field.
- Click Confirm.
From the SDK
service.versions['runner'] = ‘1.23.23.latest’
service.versions['dtlpy'] = ‘1.23.23’
service = service.update()
Execution Timeout
An execution is a single function invocation with input data. Execution has a unique ID, status, and log, allowing for monitoring from invocation to completion. Failure to complete an execution may occur for various reasons, with timeout being one of the main causes.
The timeout defines the maximum duration for executions. Once this limit is reached, the service undergoes a restart.
To ensure the completion of parallel running executions before terminating the pod, we introduce a "Drain Time" delay. After this designated period, the execution restarts.
The recommended value is less than or equal to 2500000 (in seconds). If the value exceeds it, get a timeout from RabbitMQ. Even if the value is higher than recommended, the execution will still be completed, however, the message can go back into the queue and try to run again.
Secrets for Applications
You can use Service Configuration to create or add a secret for your function. For more information, see the Secrets.
Add Secrets for Application Service
- Click the App Config button to create or edit the default service configuration.
- Go to the Secrets field, and select an existing secret from the list, or
- Click the + icon. The New Integration popup is displayed.
- Enter a unique name for your secret.
- Enter the secret value that you created at the Data Governance > Secrets page.
- Click Create.
- Click Confirm.
Preemptible
Preemptible instances are designed for short-term usage. They behave the same as regular compute instances, but can be reclaimed at any time when needed elsewhere, and can run for a maximum of 24 hours before being preempted.
If your workloads are fault-tolerant and can withstand interruptions or failures, then preemptible instances can be scheduled for your application. For example, use preemptible VMs for tests that can be stopped and resumed later or for any short-term or non-critical application.
Limitations
Preemptible instances function like normal instances, but have the following limitations:
- Compute Engine might stop preemptible instances at any time due to system needs. The probability that Compute Engine stops a preemptible instance for a system need is generally low, but might vary from day to day.
- Compute Engine always stops preemptible instances after they run for 24 hours.
- Preemptible instances are finite Compute Engine resources, so they might not always be available.
Set Preemptible instances
Once creating a new application, the computing settings will probably make your application installation (service) use preemptible instances by default.
- To update existing applications to start using Preemptible VM:
- Update the App settings:
- Select CloudOps > Services.
- Select or search the application from the list.
- Click on the Service Actions.
- Select the Edit Service Settings.
- Click Advanced.
- Enable the Preemptible option, if it is not enabled.
- Update the App settings:
- To disable Preemptible VM when creating a new application:
- Create application dialog > App Config settings > disable the Preemptible option.
Service Configuration Error
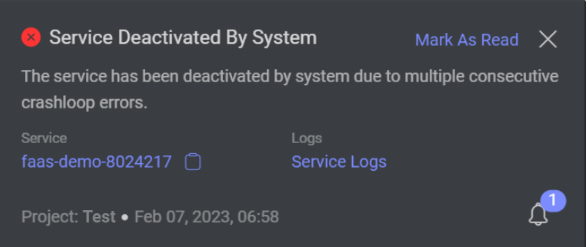
Our system is designed to reduce your computing costs by shutting down services automatically when a service is stuck in a restart loop and unable to start (scale up) due to service errors. You will receive a system notification in the notification center informing you of the deactivation, as well as a message indicating the exact error.
The Dataloop system monitors the following service errors:
- CrashLoopBackOff - Occurs as a result of a configuration error in the specified requirements (dependencies), service `init` function, codebase error, etc.
- ImagePullBackOff - Occurs when the service's container image cannot be pulled due to an invalid image name or trying to pull from an unauthorized private registry, etc.
To learn more about crash loop types, click here. For information on our notification system, click here.