A model version can be initialized as a baseline within the Marketplace catalog by selecting a specific foundation model architecture, which is usually in an untrained state initially. This allows for the flexibility to begin training the model with datasets of your choice. Once the model has been trained, it can undergo evaluation to assess its performance and effectiveness.
Following evaluation, the model can be deployed to make further predictions and annotation tasks. This process enables a streamlined approach to developing, testing, and utilizing AI models for various predictive tasks.
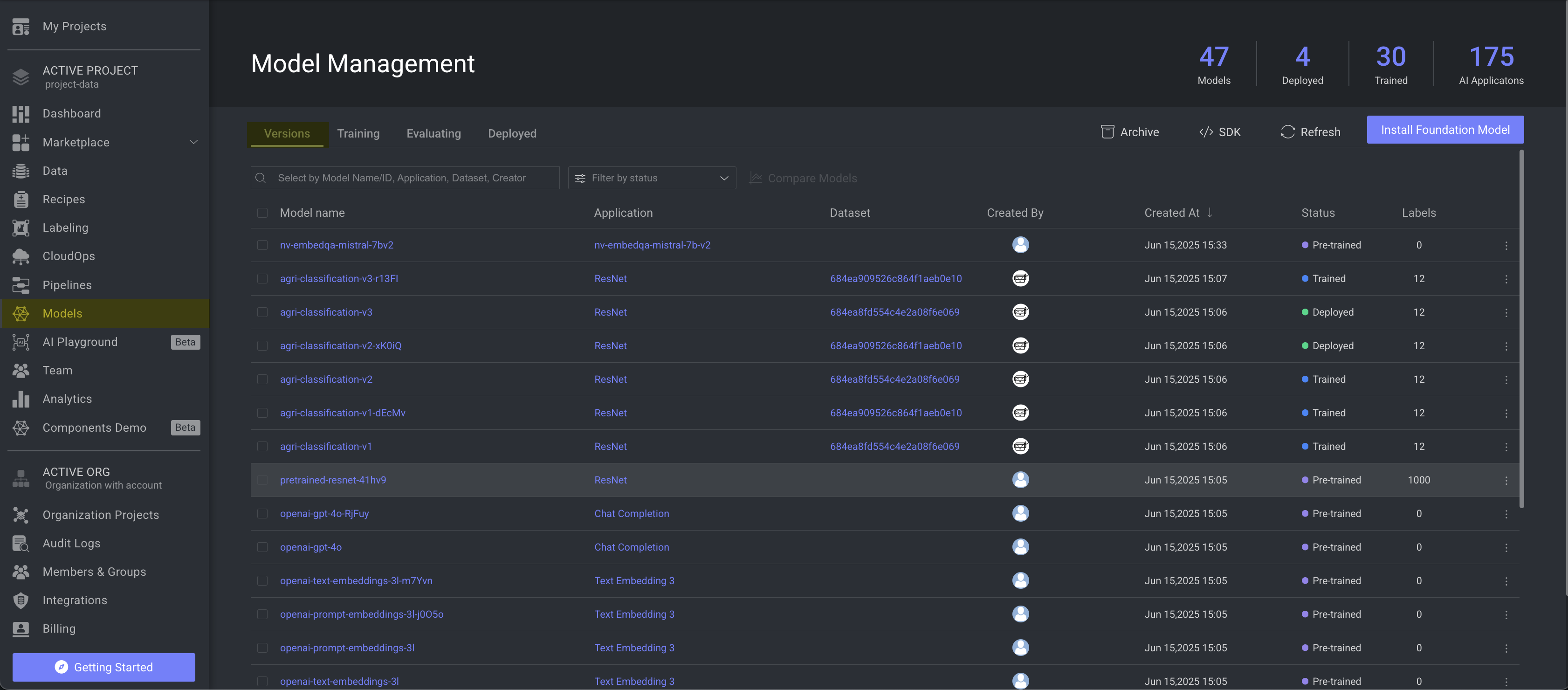
Version Table Details
After a model is installed on the Dataloop platform, it appears under the Models → Versions tab, displaying the following information:
Fields | Description |
|---|---|
Model Name | The name of the model. Click on it to open the model's detailed page. |
Application | The name of the application available in the model. Click on it to open the Manage Installations page of the Marketplace. |
Dataset | It displays the name of the dataset used to train the model. Click on it to open the Dataset Browser page. |
Created By | The avatar and email ID of the user who created the model. |
Created At | The timestamp of the model creation. |
Status | The status of the model, such as Pre-Trained, Deployed, etc. To learn more, refer to the Model Version Status section. |
Labels | The number of the labels available in the model. Labels refers to the outcomes a model is trained to predict, based on examples provided during training. These labels define the range of predictions a model can make. |
Configuration | Click on the information icon to view the available configuration. |
Tags | It lists the available tags in the model. Tags are typically served as labels or keywords associated with models to facilitate organization, filtering, and search. Tags can represent a variety of attributes or characteristics of the models. |
Search and Filter
Dataloop platform allows you to search models using Model Name, Model ID, Application Name, Dataset Name, and Creator Email ID, providing users with the capability to refine and narrow down the displayed models.
Use the Filter by Status field to filter models by status. To learn more, refer to the Model Version Status section.
Model Version Status
A model version status is indicated in the versions table, and at the Version-Details page. The status on a model version can be one of the following:
Cloning: The model version is currently in the cloning process.
Created: The model version was created but was not yet trained.
Pre-Trained: The model (entity) was trained already.
Pending: The model version is pending training. Training will begin when there are available resources on the training service (begins with 'mgmt-train' and ends with the model-id of the respective model-architecture. For example, a single service handles training for all ResNet model versions, etc.). Increase the auto-scaling factor to enable immediate training.
Training: The model version is currently training.
Trained: The model version finished the training process.
Deployed: The model version is running as an application service.
Failed: Model training failed. This could be because of a problem with the model adaptor, the training method, configuration or compute resources issues. Refer to logs for more information.
Install Foundation Models
The Marketplace's Models tab showcases foundation model architectures, encompassing organization and project scope-level models. These foundational models serve as the basis for initiating model management, installing models, versioning, and training with diverse datasets.

To install, follow these steps:
Open the Models from the left-side menu. The Versions tab is displayed.
Click on the Install Foundation Model. The Select Foundation Model window of the Marketplace is displayed.
For remaining instructions, follow the steps.
Clone Models
You can clone an existing model version to create a new one and train it with additional data.
Open the Models page.
In the Versions tab, find the model version you wish to use as a basis for a new version, and click on the
⋮3-dots action button.Select the Clone Model Version option. The Clone Model Version window will be displayed.

Enter a new name for the model and a description (optional).
Add a Tag for the new model if needed. Tags from the base model will be displayed, if available.
In the Advanced section, select the Training Artifact:
Local (default): Training data (W&B) are saved in the Dataloop file system. Provide the folder path info in the Local Path field.
Item: Provide an item-id, and training data will be saved on it.
Link: Provide a URL and the file name to save the training data on a remote server.
Make changes in the Model Configuration.
Click Clone Model. A confirmation message is displayed, and the new model version will be displayed.
Compare Models
Dataloop platform allows you to compare two or more models to analyze the parameters.
Open the Models page.
In the Versions tab, select the model versions you wish to compare.
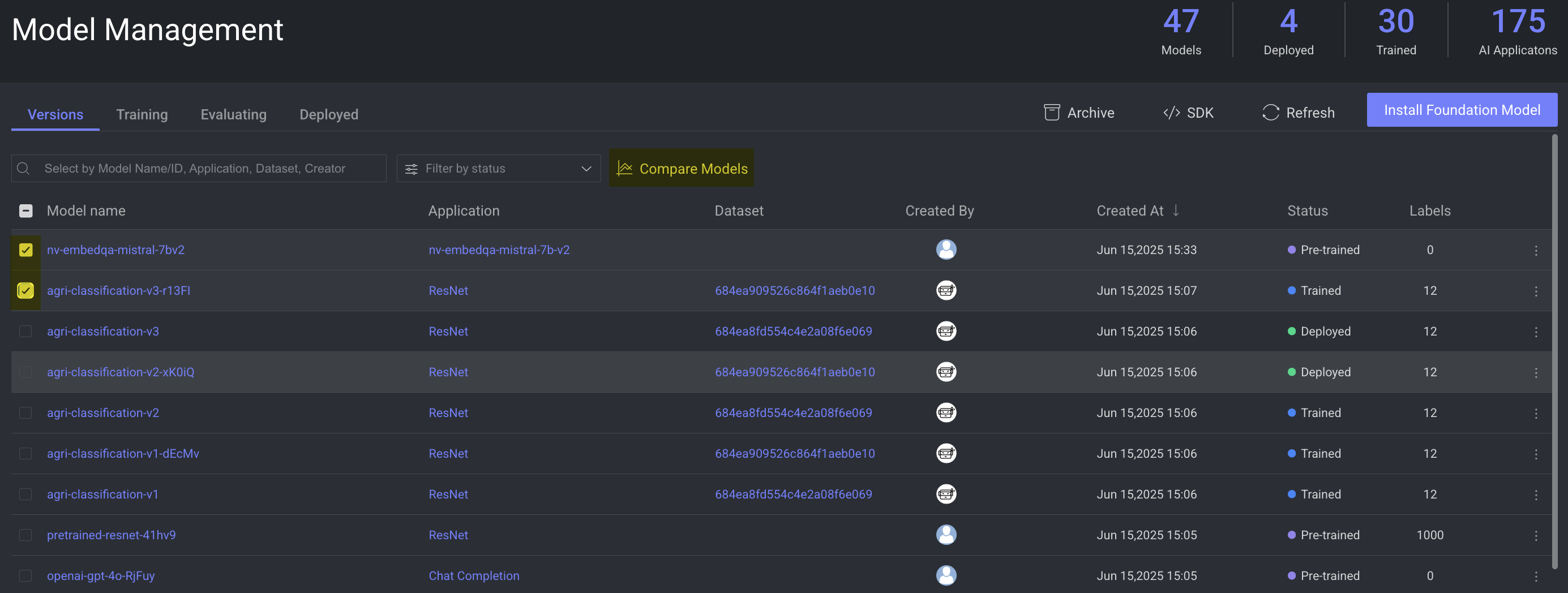
Click Compare Models enabled on the top-bar. The Multiple Models page is displayed.
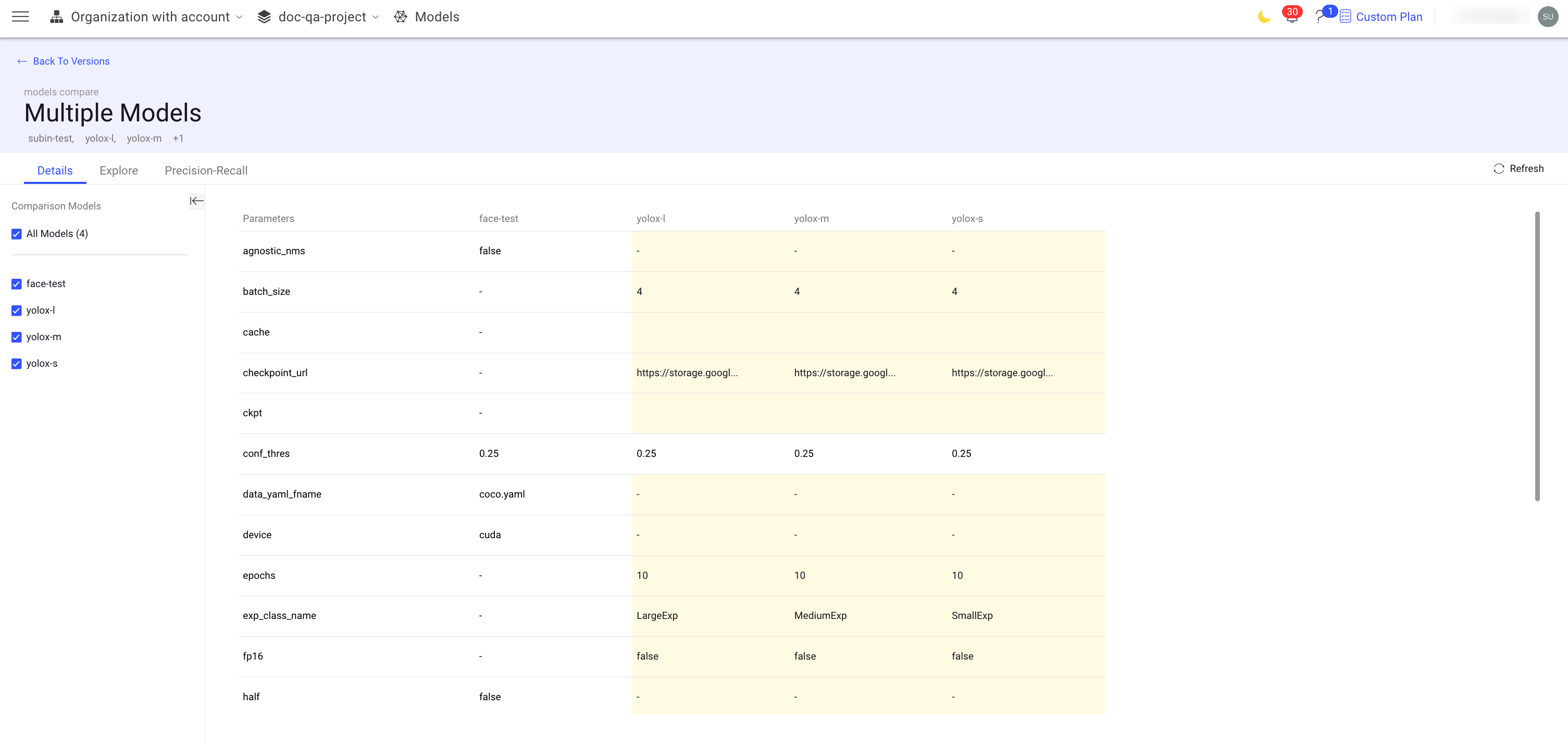
Analyze the details and parameters as required.
Train Models
Initiate the training process for a selected model version, configuring it to learn from labeled data and optimize its performance for deployment.
Open the Models from the left-side menu.
In the Versions tab, search and locate the model-version you would like to start training. You can train models that are with status created or pre-trained.
Click on the
⋮3-dots actions icon of the model, and select the Train option from the list. A Model Version Training window is displayed.
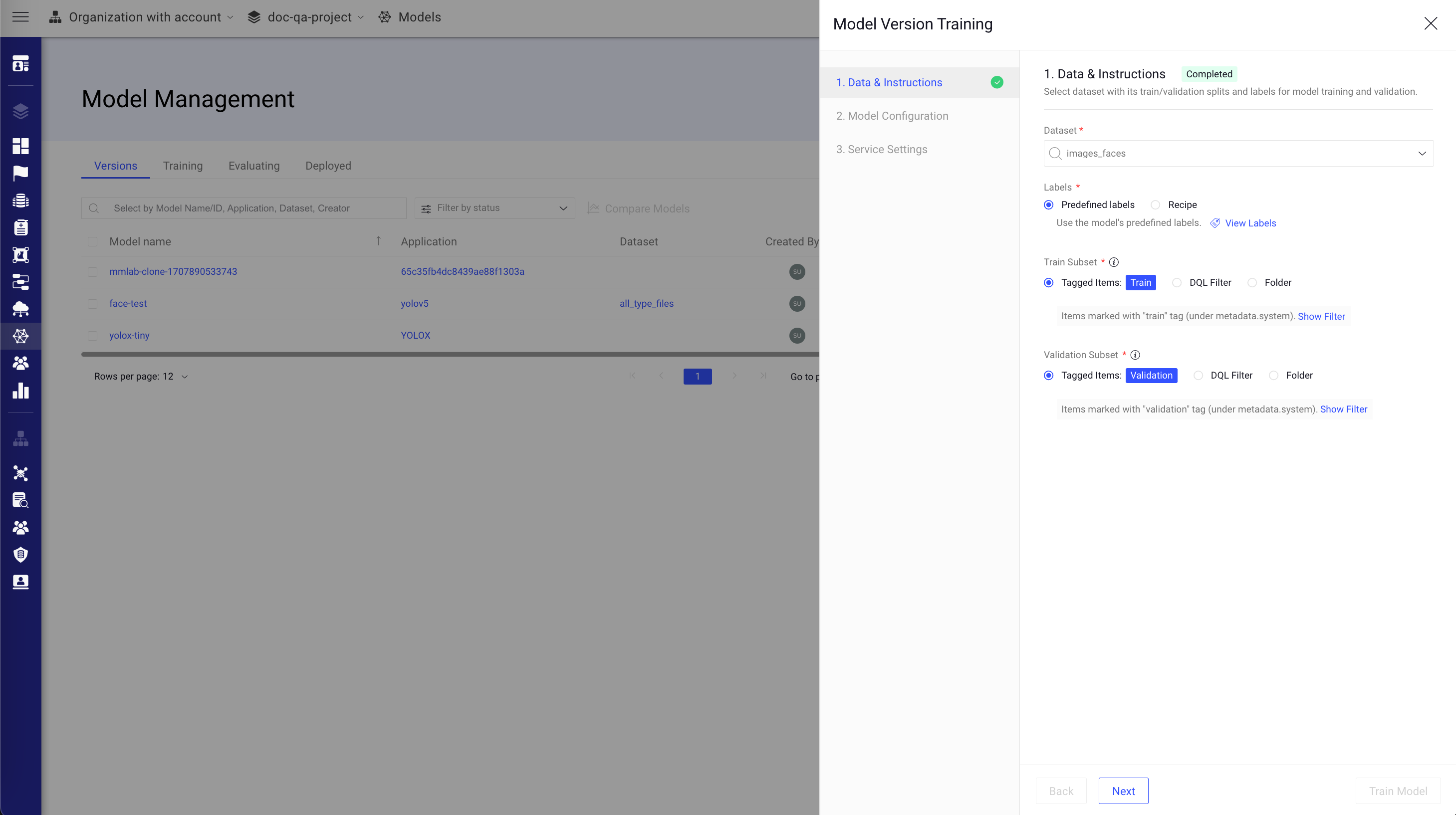
Data & Instructions: Review and make changes to the following fields in the Data & Instructions. You can select a dataset, recipe, and determine the subsets to be used as the model's training and validation sets.
Dataset: Select the dataset from the list.
Labels:
Predefined labels: If the model is not trained yet, then use the Predefined labels to train it. Click View Labels to use the model's predefined labels.
Recipe: Select a recipe for the dataset. If there is no recipe, select the Project Recipe, or click Set Recipe to create an unique recipe for your task. Annotation Managers can select the Project Recipe and view its details through Quick Preview; however, they do not have permission to open or modify the Project Recipe.
Train Subset:
Tagged Items: Select items marked with Train tag. Click Show Filter to view the filter.
DQL Filter: Select a saved DQL filter.
Folder: Select a specific folder to define the data scope for the train subset.
Collections: Select collections from the list. It allows you to select items from the collections.
Validation Subset:
Tagged Items: Select items marked with Validation tag. Click Show Filter to view the filter.
DQL filter: Select a saved DQL filter.
Folder: Select a specific folder to define the data scope for the validation subset.
Collections: Select collections from the list. It allows you to select items from the collections.
Default Filter Selection Logic
If the model has predefined filters: Compare them (without spaces/line breaks) with the ‘Tagged Items’ filter.
If it matches: Select ‘Tagged Items’ by default.
If it does not match: Default to ‘DQL Filter’.
If there are no predefined filters, select ‘Tagged Items’ by default.
Click Next button. The Model Configuration section is displayed.
Make required changes and click Next: Service Settings.
Make required changes in the Service Settings section. Refer to the Edit Service Settings section for detailed information about the available fields.
Once you complete, click Train Model. A confirmation message is displayed.
Train a Model After Creating It
When creating a new model version, train the model after creating by selecting the Create & Train button.
Evaluate Models
Assess a trained model’s performance by running it on labeled datasets to measure accuracy, precision, recall, and other evaluation metrics.
Prerequisites
To be able to evaluate a model, you first new to make sure:
The models are located in any of your projects. Public models cannot be evaluated directly (you first need to import them yo your project).
The models must be Pre-Trained, Trained, or Deployed.
The model owns predict() function.
To evaluate a Pre-Trained, Trained, or Deployed model version:
From the Models -> Versions tab, search and locate the model-version you would like to start evaluating.
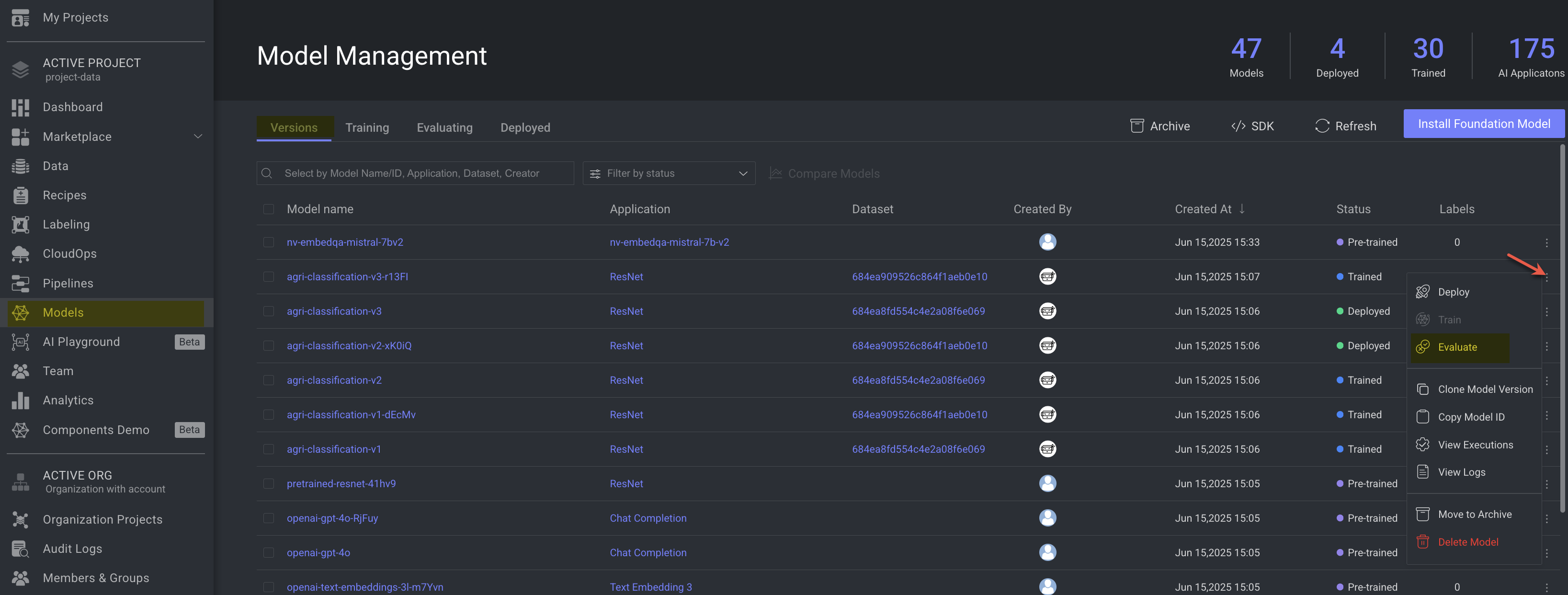
Click on the
⋮3-dots actions icon of the model, and select the Evaluate option from the list. A Model Version Evaluation window is displayed.In the Evaluation:
Dataset: Select a Dataset from the list to use it for the evaluation. By default, the model's dataset is displayed.
Test Subset:
Tagged Items: Select items marked with Test tag (learn more). Click Show Filter to view the filter.
DQL Filter: Select a saved DQL filter.
Folder: Select a specific folder to define the data scope for the test subset.
Collections: Select collections from the list. It allows you to select items from the collections.
Click Next button. The Service Settings section is displayed.
Make required changes in the Service Settings by referring to the Edit Service Settings section.
Once you complete, click Evaluate Model. A confirmation message is displayed.
Deploy Models
Activate a trained or pre-trained model version by deploying it to a live environment, enabling inference and integration within data pipelines or annotation workflows.
Open the Models from the left-side menu.
In the Versions tab, select the model that you intend to deploy. You can deploy only models that are:
Pre-trained: A model trained externally (e.g., open-source or third-party) and uploaded to Dataloop.
Trained: A model that has completed training within Dataloop.
Deployed: A model that has already been deployed (possibly for re-deployment into a new environment, updates, or rollback).
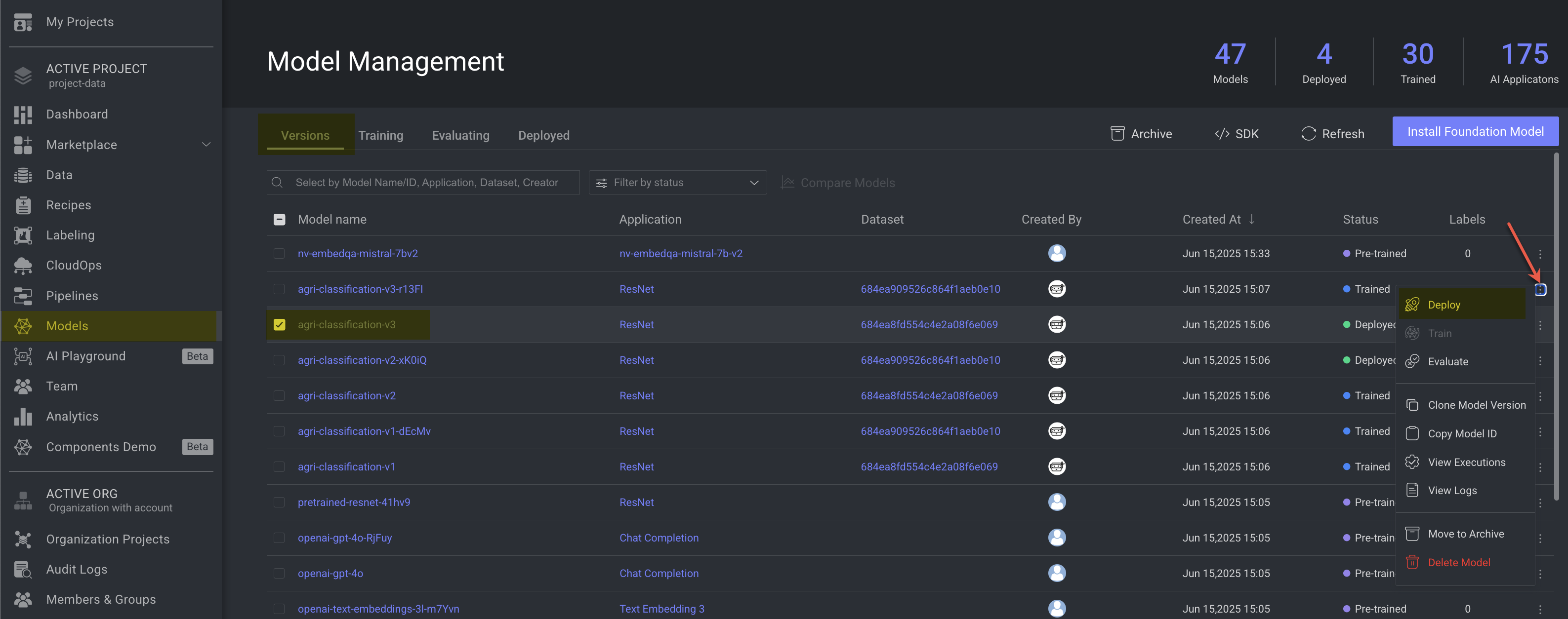
Click on the
⋮3-dots action icon, and select the Deploy option from the list. The Model Version Deployment panel is displayed.
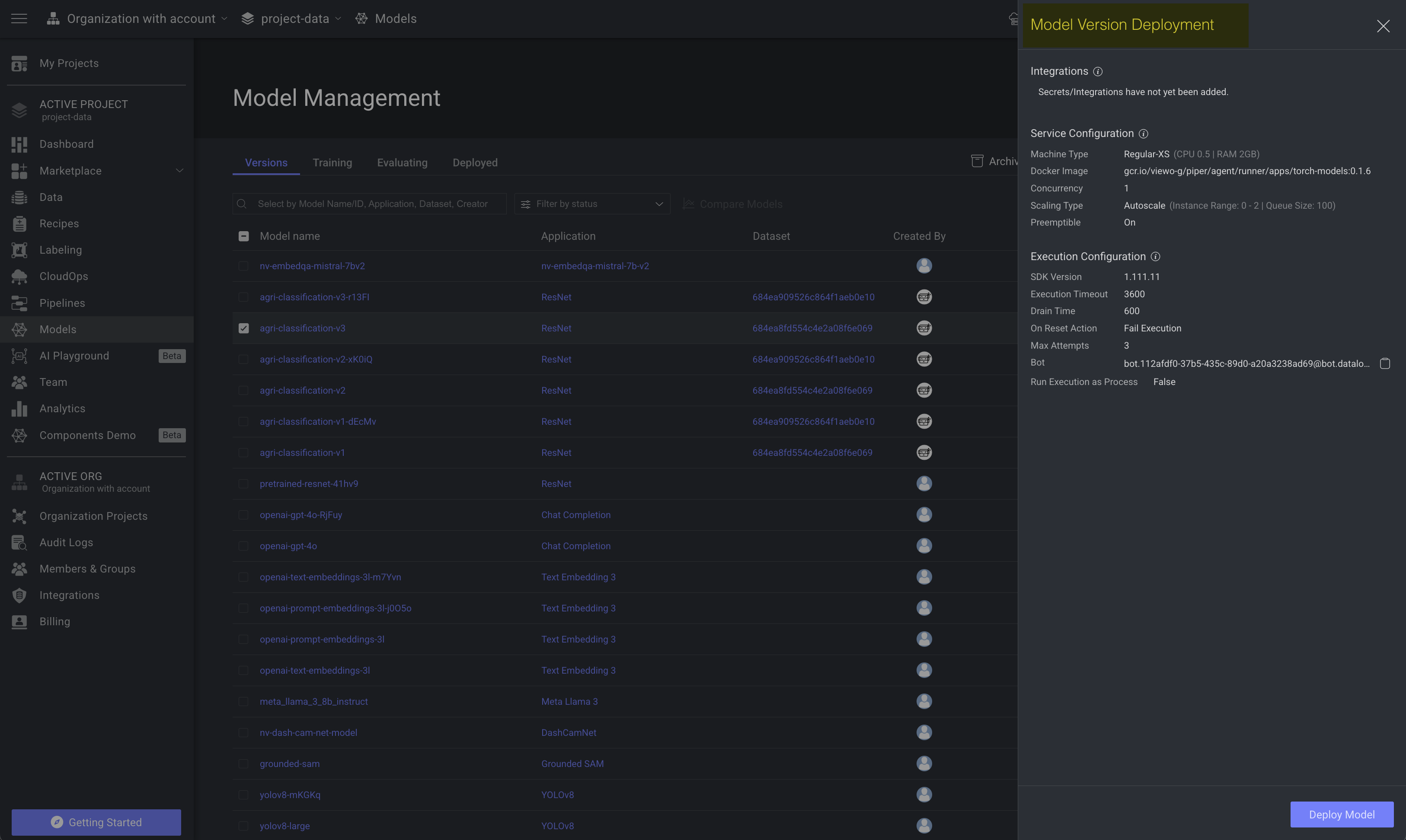
Make required changes in the Service Settings section. Refer to the Edit Service Settings section for detailed information about the available fields.
Once you review the above parameters, click Deploy Model. A message will pop up when the model is deployed and ready as a service.
Model Details
Model-Version has an internal details view, with more information about the model-version.
To access the model-version details view, click a model version from the Versions table.
The model-version details view includes four tabs:
Details
Contains information about the model, such as:
Model creation date and creator details.
Tags: shows tags currently on the model version, allowing you to add additional tags or remove existing ones.
Labels used in the model - review and search for labels.
Model configuration.
Explore
The Explore tab displays the metrics generated during the training process, or metrics uploaded by SDK to store on the model-version. Also, it lists the datasets used to train the model. To learn more, refer to the Training Metrics article.
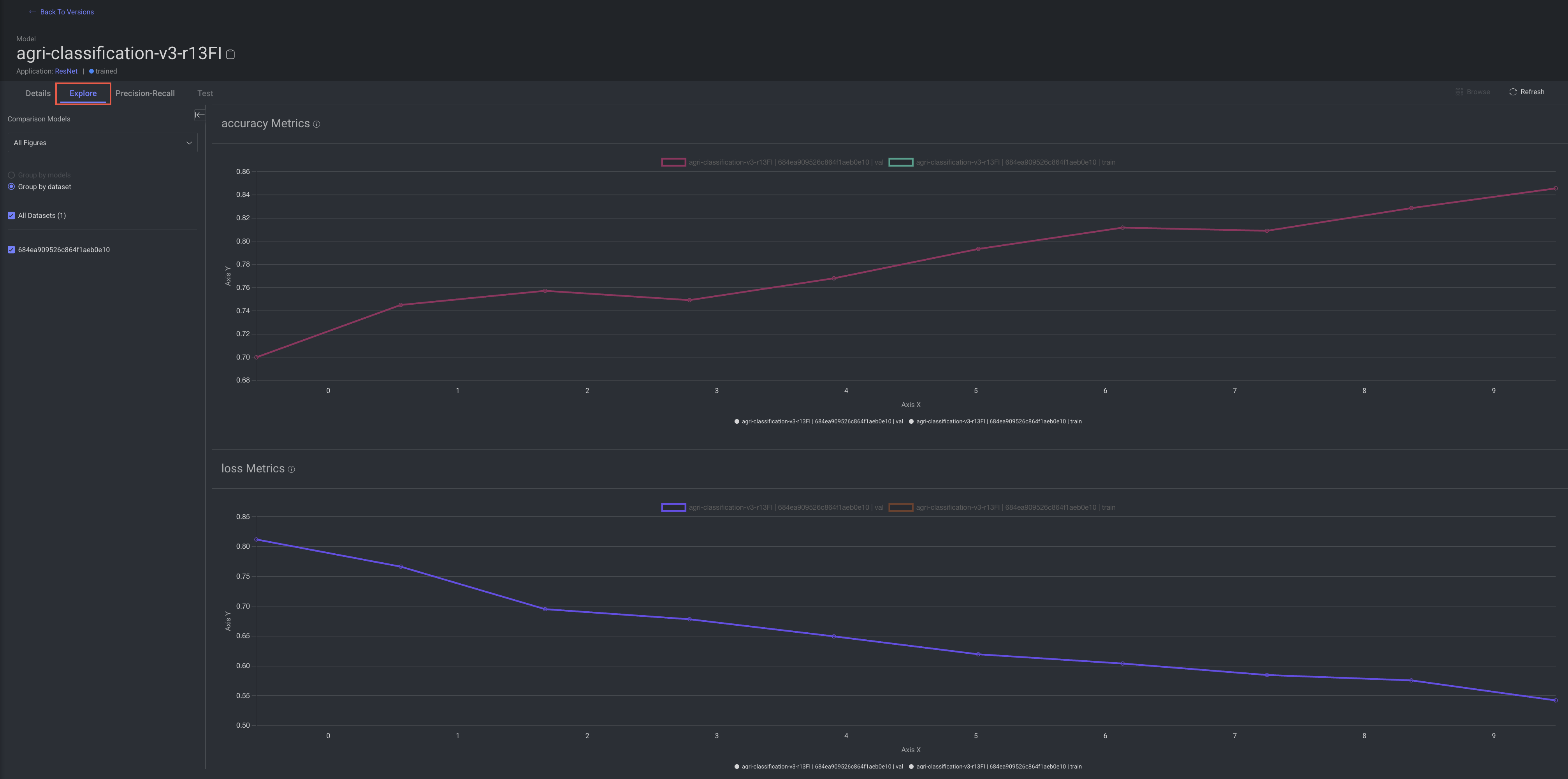
Precision-Recall
Precision and Recall are two critical metrics used to evaluate the performance of an AI model, especially in tasks like classification where the outcomes are categorized as positive (relevant) or negative (irrelevant). These metrics are particularly useful in scenarios where the classes are imbalanced (i.e., one class is significantly more frequent than others).
You can measure precision and recall values after setting up a model evaluation. To set up a model evaluation, refer to the Model Evaluation article.
Visualizing accuracy
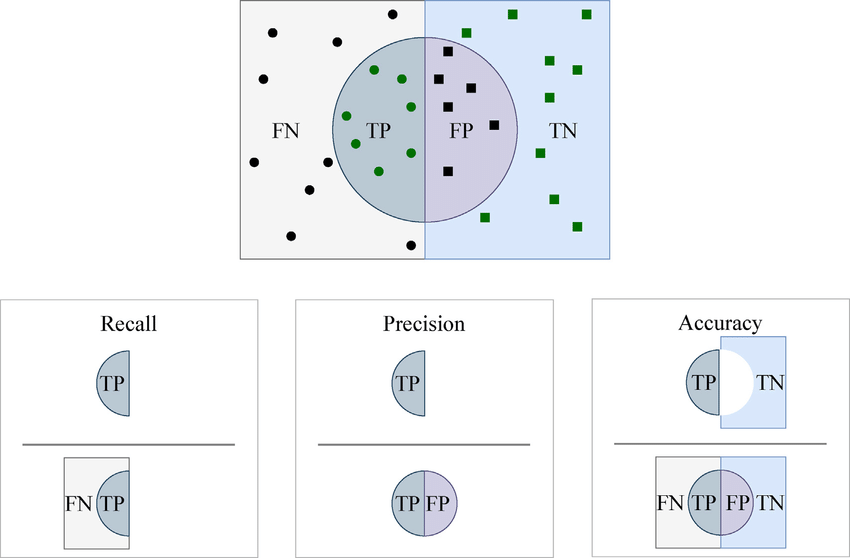
Visualizing accuracy, recall (aka sensitivity), and precision, which are the common performance measures for classification tasks. Given samples from two categories, we can refer to samples as positive or negative (two classes). The left rectangle represents positive samples, and the right rectangle represents negative samples. The circle contains all samples predicted as positive. Given the model predictions, each sample can be considered as TP (true positive), TN (true negative), FP (false positive), or FN (false negative).
Precision recall curve
The Precision-Recall Curve is a plot that illustrates the trade-off between precision and recall for different thresholds. A higher area under the curve (AUC) represents both high recall and high precision, where high precision relates to a low false positive rate, and high recall relates to a low false negative rate. This curve is particularly useful for evaluating models on imbalanced datasets.
Precision by confidence threshold
Demonstrates the performance of your model for the highest-ranked label across the entire spectrum of confidence threshold levels. Raising the confidence threshold leads to a reduction in false positives, enhancing precision. Conversely, lowering the confidence threshold results in a decrease in false negatives, thereby improving recall.
Precision
Precision, also known as positive predictive value, measures the accuracy of the positive predictions made by the model. It is the ratio of true positive predictions to the total positive predictions (including both true positives and false positives). In simpler terms, precision answers the question: "Of all the instances the model labeled as positive, how many are actually positive?"
Precision
= (True Positives (TP)/(True Positives (TP) + False Positives (FP))
High precision indicates that the model is reliable in its positive classifications, making few false positive errors.
Recall
Recall, also known as sensitivity or true positive rate, measures the model's ability to correctly identify all relevant instances. It is the ratio of true positive predictions to the total actual positives (sum of true positives and false negatives). Essentially, recall answers the question: "Of all the actual positive instances, how many did the model correctly identify?"
Recall
= (True Positives (TP)/(True Positives (TP) + False Negative (FN))
High recall indicates that the model is good at detecting positive instances, minimizing the number of false negatives.
Test
The Test tab is to allow users to directly interact with a deployed model to assess its inferencing capabilities on new, unseen data. This is crucial for understanding how the model performs outside a controlled training environment.
The Test tab is to allow users to directly upload images and click Test to start the model prediction process.
Testing a deployed model by uploading a file for inferencing involves evaluating the model's performance and behavior on new data that it hasn't seen during the training phase. This process helps verify that the model accurately interprets and analyzes the data, providing expected outcomes based on its learned patterns.
Why Test a Deployed Model?
Testing a deployed model is crucial for several reasons:
Accuracy Verification: Ensures that the model performs as expected on real-world data.
Performance Evaluation: Helps identify any latency or computational performance issues that may not have been evident during the development phase.
Feedback Loop: Provides valuable information that can be used to further refine and improve the model.
Uploading a File for Inferencing: Users can upload a file that the model will use to make predictions. The file type and content depend on the model's purpose (for example, images for a vision model, text files for natural language processing, etc.).
Update Model Configurations
Open the Models page.
In the Versions tab, click on the model name that you wish to update the model configuration. The Details tab of the model version is displayed.
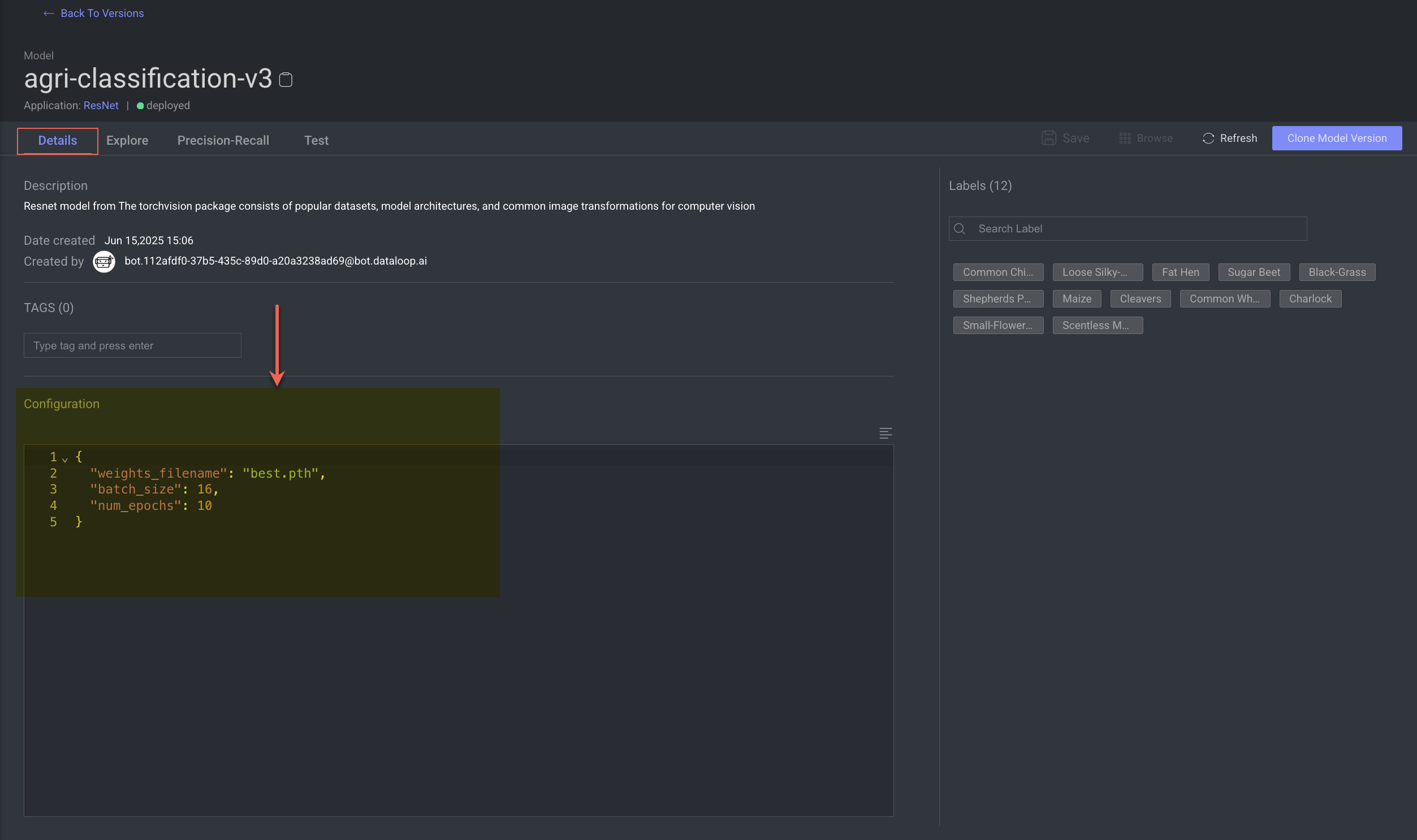
In the Configuration section, make the required changes, and click Save. A confirmation message is displayed for the models that are deployed:
Update all related services: Choose this option to apply the change to all related services.
Do not update any service: Choose this option to not to apply the change to any related services.
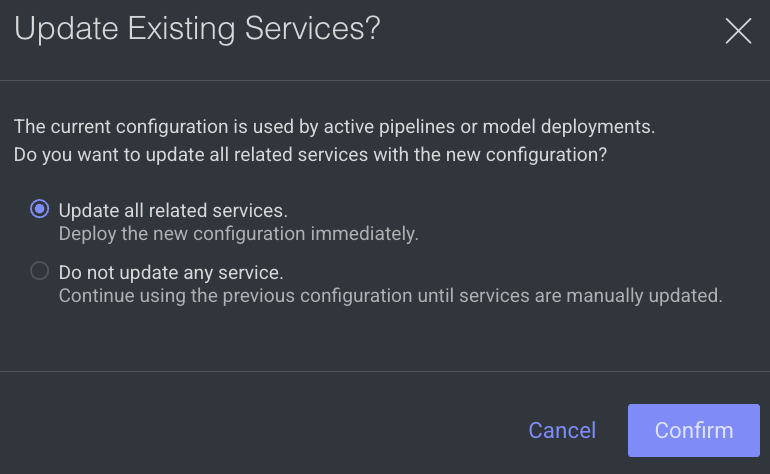
Click Confirm. A confirmation message is displayed.
Archive Models
As you experiment and create a model version, choosing your path forward can sometime mean that some model versions are no longer required. Removing them from the model-versions list will simplify it and improve your ability to filter and search for the versions you really need.
Open the Models page.
In the Versions tab, find the model version you wish to use as a basis for a new version, and click on the 3-dots action button.
Select the Move to Archive option from the list. A confirmation message is displayed.
Click Yes. A confirmation message is displayed.
Restore Archived Versions
Open the Models page.
In the Versions tab, and click on the Archive button. The Archived Models page is displayed.
Review archive model versions, search and locate the model-version you wish to restore.
Click on the 3-dot action-button on the right-side, select the Restore option and confirm the operation in the pop-up window.
The model-version is now restored and can be found in the main Versions tab.
Debugging Tool - VS Code
VS Code in Dataloop offers an integrated environment for debugging model application active services. It features a built-in code editor that allows you to view, edit, and debug code directly within the same platform where your model applications are developed and deployed. For more information on the service debugging, refer to the Service Debugging (VS Code) page.
Find the Model Services and Open the VS Code
From the Model Management Page
Click on the Service either from the Training, Evaluating, or Deploying tab. It opens the CloudOps → Monitoring page.
Click Service Actions, and select the Open VS Code from the list.
From the CloudOps
Open the CloudOps from the left-side menu.
In the Services tab, Click on the Search by Context field.
Select the
modelfrom the list.Select either model
idornameto filter the service.
.png)